Realizar OCR
tip
Essa página tem como função explicar o processo de digitalização e edição de um livro, para que o arquivo se torne de fácil visualização para estudo e pesquisa, além de ser possível pesquisar palavras-chave. Neste tutorial, as etapas são feitas no acesso remoto do LabRI/UNESP.
É importante que as etapas sejam seguidas na ordem listadas!
KRename
- KRename é um software de renomeação de arquivos em lotes. Ele é necessário nesse processo para que as páginas escaneadas sejam nomeadas de acordo com a sua ordem, e o processo de transformação em PDF não desorganize as páginas. O KRename está disponível no ambiente virtual do LabRI/UNESP no Menu > Acessórios > KRename.
- Ele é o primeiro passo que deve ser realizado após o escaneamento do livro.
- Após abrir o programa, clique em "Adicionar" e selecione a pasta onde o livro escaneado está armazenado. Note que ela deve estar no ambiente virtual. Na seleção "Ordenar", selecione a melhor opção para deixar as páginas em ordem, geralmente será "Crescente" ou "Numérico".
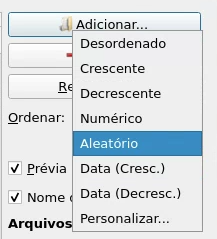
Vá direto para a aba "4. Nome do arquivo", você não precisará alterar as abas 2 e 3. Em "Prefixo", coloque Número. Mantenha "Sufixo" em branco, "Nome do arquivo", coloque "nome personalizado" e "Extensão" coloque "Usar extensão original". As configurações estão ilustradas na imagem abaixo.
Em "Número de dígitos", coloque sempre um número que faça com que as últimas páginas continuem com um zero na frente. Portanto, se o livro tiver entre 100 e 1000 páginas, o número de dígitos será 4. Dessa forma, para um livro de 254 páginas:
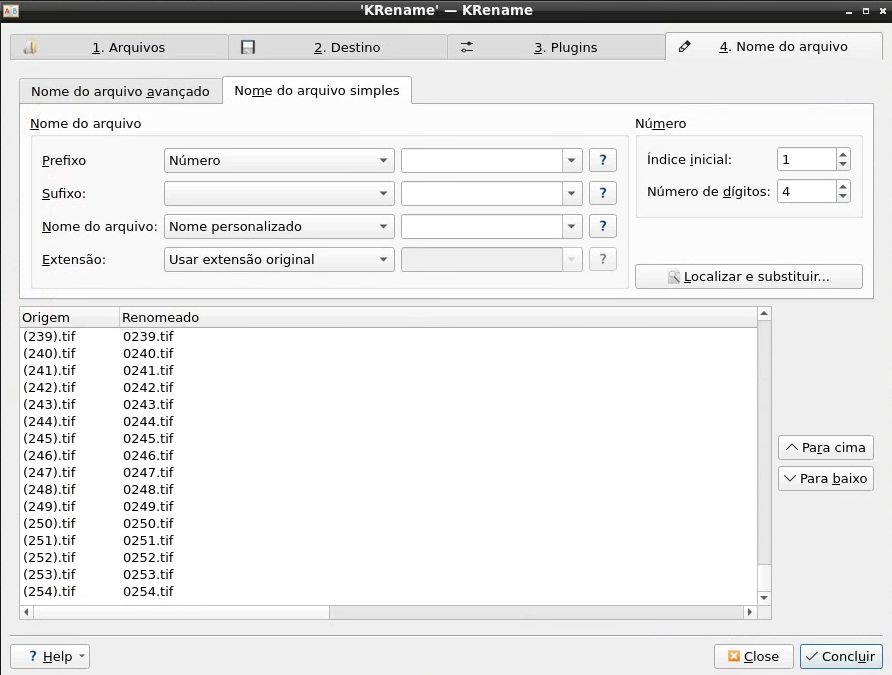
- Feito esse processo, clique em Concluir e aguarde o carregamento. Após, os arquivos estarão renomeados e prontos para serem tratados no ScanTailor na ordem certa das páginas.
ScanTailor
- Agora, é preciso editar o formato páginas e corrigir qualquer imprecisão. Para isso, abra o Terminal e digite o seguinte comando para abri o ScanTailor:
flatpak run com.github._4lex4.ScanTailor-Advanced
- Selecione a pasta onde se encontram os arquivos digitalizados. Repare que será criado uma pasta chamada “out” onde ficarão salvos os arquivos editados pelo ScanTailor.
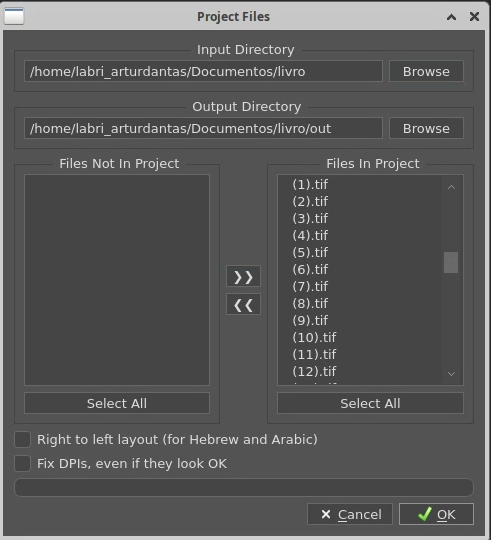
- Aqui, na maioria das vezes não é necessário configurar nada, o programa já entende o que deve ser feito, apenas clique no “play” de cada etapa e aguarde os respectivos carregamentos. Ao final, não é necessário salvar o projeto, os arquivos são salvos automaticamente.
Conversão para PDF
- Agora, precisamos passar os arquivos digitalizados de TIFF para PDF. No Terminal, acesse a pasta onde estão os arquivos já editados pelo ScanTailor. Execute o comando
img2pdf -o <nome_pdf>.pdf *.tif
trocando o nome_pdf para o nome do novo arquivo que deseja.
Realização do OCR
- Com os arquivos tratados e otimizados agora vamos realizar o Reconhecimento Óptico de Caracteres (OCR). Basicamente, o OCR é responsável por identificar os caracteres presentes na imagem e por tornar estes caracteres passiveis de busca por palavras chaves. Para saber mais sobre OCR clique aqui.
- O Tesseract é o software de código aberto mais popular para a realização de OCR. No LabRI/UNESP utilizamos um programa escrito em python chamado OCRmyPDF para fazer este trabalho. Ele utiliza o Tesseract trazendo algumas facilidade de uso e funcionalidades adicionais.
- Para fazer o OCR e tornar o PDF pesquisável, ainda no terminal e na pasta do arquivo execute o comando
ocrmypdf -l por --jobs 4 <nome_arquivo>.pdf <nome_arquivo>_ocr.pdf --force-ocr
trocando o nome_arquivo para o nome do arquivo PDF.
👉 OBSERVAÇÃO: A palavra "por", no código, se refere ao idioma do texto. "por", no caso, é usado quando o texto está em português. Deve ser trocado por "eng" ou "spa", quando o texto estiver em inglês e espanhol, respectivamente.👈
- Caso prefira, você pode seguir as instruções do vídeo tutorial.
Cortar o arquivo
- Se o arquivo que esta sendo processado é um arquivo com muitas páginas e partes (por exemplo, livros, documentos e afins) e será indexado por programas como o Recoll é importante separar este arquivo em partes menores (por exemplo, separar um livro por capítulos)
- Esse processo é importante para que o programa que indexa os arquivos consiga estabelecer mais adequadamente a relevância, de acordo com seu algoritmo, dos arquivos que serão retornados quando é realizado uma busca por palavras chaves.
- A inclusão de marcadores no inicio de cada capitulo, por exemplo, viabiliza este separação.
- Para mais instruções sofre a inclusão dos marcadores basta assistir o vídeo tutorial.
- Nós termos fizemos um script em python para realizar o processo de divisão do arquivo a partir dos marcadores presentes no mesmo.
- Também é possivel utilizar programas como o PDFsam para realizar este passo. Para poder cortar o arquivo em capítulos será necessário utilizar o aplicativo PDFsam. Para entender melhor siga as instruções do vídeo tutorial.